Notre boîte noire
L'analyse augmentée des données
La smart data ou l'exploitation intelligente des données est au cœur de l'évolution de notre métier. L'augmentation exponentielle des données et la multiplicité des sources d'informations disponibles nécessitent de recourir à des techniques d'intelligence artificielle pour faire le tri au sein de la masse de données non structurées ou issues du Big Data, pour ne retenir que celles qui sont pertinentes dans un objectif précis.
Il s’agit ainsi :
- d’améliorer la qualité des données par des traitements automatiques ;
- de vérifier et recouper les informations disponibles en les comparant notamment avec les données ouvertes ;
- de découvrir de nouvelles informations pertinentes au sein des données ;
- de créer des modèles prédictifs pour mieux anticiper ou enrichir automatiquement les données.
Même si elles sont complexes, ces technologies permettent in-fine d’offrir à l’utilisateur final des outils simples. Il peut ainsi gagner en efficacité dans son travail quotidien, analyser une situation ou augmenter son champ de vision : exploration interactive des données, recherche d’informations pertinentes, alertes automatiques, analyses et visualisations synthétiques, actualisation des indicateurs, prédictions.
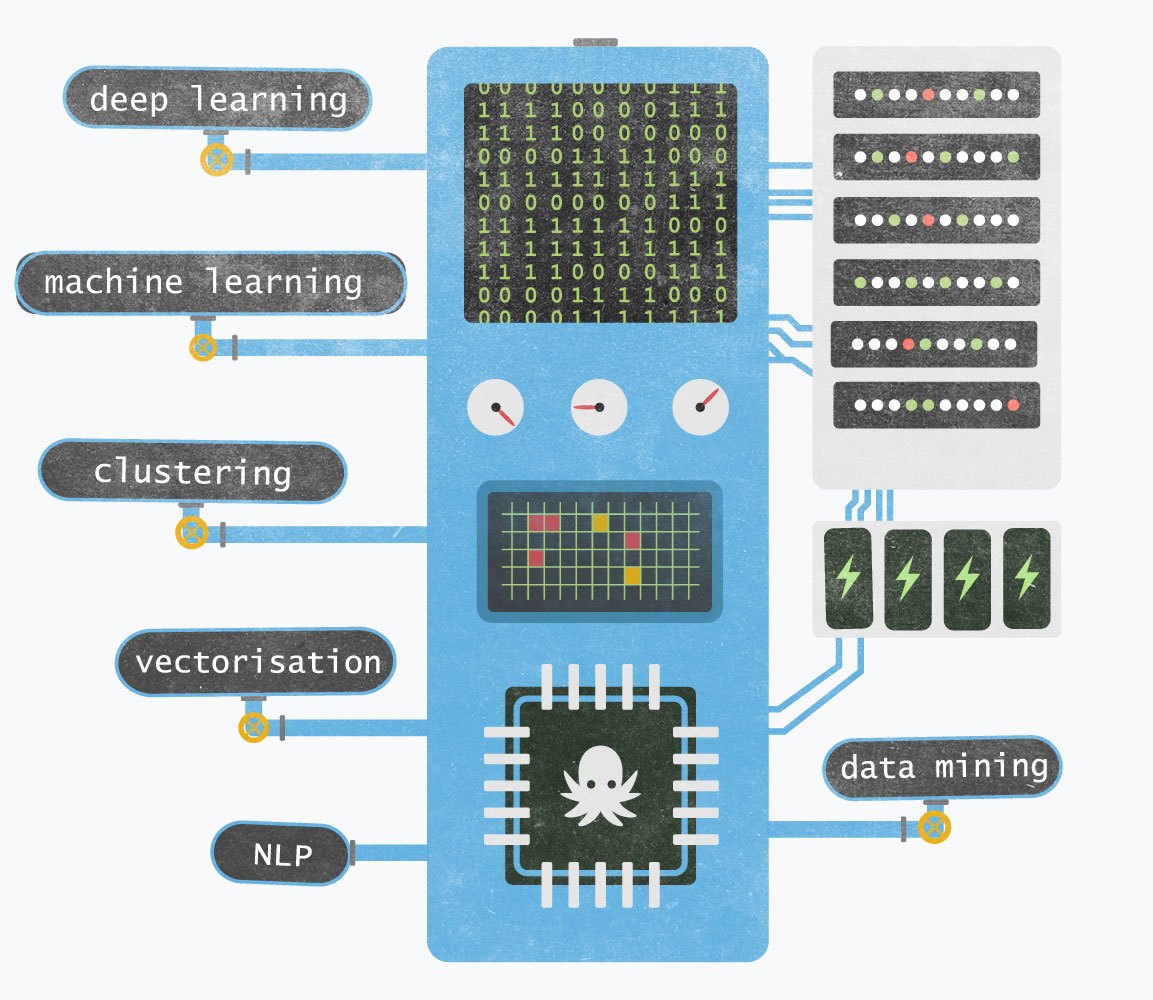
Chez OctopusMind, cette analyse est au service de la détection des opportunités d’affaires et de l’exploration de l’environnement économique, avec J360. Elle peut également être au service des collectivités et citoyens, comme avec CityZenMap. L’analyse augmentée (augmented analytics) repose sur les technologies du Machine Learning et du traitement automatique du langage naturel pour automatiser la préparation de données, la découverte et le partage de perspectives analytiques. Son principal avantage est de permettre aux analystes de gagner beaucoup de temps (voir la synthèse du rapport Gartner « Augmented Analytics Is the Future of Data and Analytics », publiée le 27 juillet 2017.
Les analyses, qui consomment d’ordinaire beaucoup de temps et de ressources, peuvent être fortement simplifiées et accélérées grâce à cette technologie.
L’apprentissage profond (Deep Learning) permet de construire des modèles sémantiques.
On analyse l’information textuelle mixée à des données hétérogènes par projection dans un espace sémantique commun.
L’extraction de données et de relations, permet d’accéder à des millions d’informations enfouies dans le texte.
On peut ainsi calculer des indicateurs, structurer, rendre compte et prédire.
Notre usage de l'intelligence artificielle
En route pour un tour rapide des technologies de notre "boîte noire" :
Notre matière première est la donnée. Elle va être moissonnée par des robots (web scraping), téléchargée à partir de sources open data , requêtées à partir du web sémantique ou de corpus de références, ou obtenues par production participative (crowdsourcing).
Nous utilisons Elasticsearch pour chercher et analyser ainsi que nos propres outils d'« analyse intelligente » des données issus de techniques de Machine Learning et du traitement automatique du langage (NLP). Pour les connaisseurs, voici quelques-uns de nos secrets :
- analyse des principaux composants (PCA)
- partitionnement automatique (Data clustering)
- forêts d’arbres décisionnels (random forests)
- champs aléatoires décisionnels (CRF) et surtout réseaux de neurones sous de multiples formes (perceptrons multi couches (MLP), réseaux de convolution, auto-encodeurs, réseaux récurrents…)
Une boîte à outils très complète et en constante évolution qui ouvre de multiples possibilités sur un jeu de données, qu’il soit structuré ou non :
- association automatique des données (similarité, recommandation)
- extraction d’informations textuelles sous forme structurée (localisation, données quantitatives, qualifications catégorielles, suppression du bruit)
- catégorisation automatique des données, suivant des axes multiples
Tous ces outils, combinés à notre expertise, nous permettent de proposer un service qui augmente la compétitivité de nos utilisateurs.
Nos présentations
Fouille de texte
Article sur notre modèle de vectorisation LSA+W2V à l’EGC 2019, conférence francophone qui porte sur l’extraction et gestion des connaissances.
Voir le PDFFouille de texte
Vidéo de présentation de notre modèle de vectorisation LSA+W2V à l’EGC 2019.
Voir la vidéoMettez Elasticsearch à votre service
Découverte d'une partie des possibilités qu'offre Elasticsearch du point de vue du développeur.
Voir la vidéoAprès Jupyter Notebook, voici JupyterLab
Présentation du notebook Jupyter et son successeur JupyterLab, des nouveautés et de quelques cas d'utilisation.
Voir la vidéoLe TAL appliqué à l'open data économique
Webminar sur la classification de textes, mécanisme d'attention et extraction de relations entre entités nommées.
Voir la vidéo